I realized that my research style has evolved into this highly-empirical, inductive, ablation-heavy, and rigorous-to-a-fault nature. It’s good and I think that’s where my strengths lie especially given my experience in frontier LM training, but I’m starting to realize that this style is unsustainable in an environment where compute is scarce (e.g., academia): you can’t do all the ablations you want, no matter how creative you can be.
This term, I am slowly shifting towards more theory-heavy approaches. This is quite exciting, as I think these are the types of work that can only be done in an academic setting (industry will always ask: “how can we apply this at the present moment?"). Recently, I’ve been interested about geometric ML, I think it’s pretty cool.
The enshittification of LLMs began when chat models started asking leading questions at the end of their response to prompt you to continue the conversation
Multiple identities
It’s my fault: I have three profiles in ACL right now. Hassle! I tried making a PR but turns out the alias is not a “Rename” but a “Symlink.” Back then I never really thought hard about which name I’d use: LJ Miranda, Lester James Miranda, Lester James V. Miranda, or Lester James Validad Miranda.
- https://aclanthology.org/people/l/lester-james-validad-miranda/
- https://aclanthology.org/people/l/lester-james-v-miranda/
- https://aclanthology.org/people/l/lj-miranda/
My OpenReview profile shows Lester James Validad Miranda. The name in the paper is Lester James V. Miranda. Then there are some papers with LJ Miranda or Lester JV Miranda (sad, it’s from a large collab and I saw the change after the camera-ready).
Ok, from now on: I’ll keep my OpenReview as Lester James Validad Miranda and I’d prefer that my name is written as Lester James V. Miranda in papers.
My secret academia goal now is to get into the ACL committee and be like that engineer who fixed an annoying bug and left:

Or I can just make another PR.
I’m now a uv convert. I haven’t really updated my Python tooling and workflow for the past two years.
In fact, I’ve been using the same workflow ever since I started working:
python -m venv venv
source /venv/bin/activate
# While in venv
pip install -r requirements.txt
But there’s a lot of limitations in this workflow. For example, I’m limited by the Python version installed in my machine or it’s hard to just install ad-hoc dependencies for my one-off scripts. This workflow also doesn’t manage dependency conflicts, I still remember those days when I’m checking whether I should use X version of pytorch or Y version of spaCy to get things running.
The uv tool solves all of that.
-
First,
uv syncdoes all the dependency management under the hood, and it automatically installs everything in a virtual environment. I was surprised how fast the installation is, compared to your good oldpip install. Really awesome! Adding new requirements is a breeze too viauv add: I just need to think about the name of the dependency, anduvwill figure out the correct version to use. -
What’s magical for me is that the virtual environment can have its own python version. So if a project needs 3.10 and I have 3.12, I can just set
3.10in a.python_versionfile (and also in mypyproject.toml), anduvwill automatically install the correct python version and dependencies. -
The best feature for me is on adding one-off dependencies for my ad-hoc scripts. This is really cool because my standalone scripts can be wholly separated from the rest of my project. When I organize my research code, I often have a separate folder for managing all my plotting code, and sometimes these only use pandas and matplotlib. I can just specify those dependencies and run the script in isolated fashion.
Yeah, uv is cool. For the past two years I never shifted to tools like poetry or pyenv, I find them quite bulky and cumbersome to use. However, uv’s interface feels lightning fast. The folks at astral are real geniuses!
Don't you dare go Hollow
I was in the middle of a Dark Souls playthrough back in 2022 when I told myself I’d apply for PhD programs in 1-2 years. I wasn’t able to finish the game and stopped before the Tomb of the Giants.
Now, it’s 2025 and I’m about to start my PhD soon! And I’ve also just beaten Dark Souls! It took me a long time to get to this point for both–with a lot of challenges, setbacks, and unconventional paths. I guess I never went full Hollow.
P.S. Also found this super nice study about Dark Souls published in CHI!

Overleaf was down a few hours before the EMNLP and NeurIPS deadlines. Today, OpenReview is down a few days before the end of the discussion period (note that we need to post rebuttals a few days before the deadline in order to engage reviewers with the discussion).
If these are due to server load, I think it’s time to revisit whether our research platforms can handle the increasing load and submissions for the coming years.
Just finished Clair Obscur Expedition 33!
I don’t know where to start—at its core, E33 is a game about family: either forged in blood or in bonds. Probably one of the best games I’ve played in a long time. It’s a really strong GOTY contender.

My favorite app right now is the (Not Boring) Camera. I like the skeuomorphic and tactile design it has that runs counter from the early 2010s Material Design UI. Also, the filters are so pretty. I’ve been thinking of buying a film camera but I’m really more of a composition »> everything so I might stick to this for a bit.

Our Seattle Food Recommendations
In no particular order, here’s our (Avic and I) list of Seattle food recommentations!
Kwanjai Thai
kwanjaithaicuisine.com
469 N 36th St, Seattle, WA 98103
Order the Pad Thai and Satay Chicken
Kirei Poke
3515 Fremont Ave N b, Seattle, WA 9810
I prefer the Dynamite Bowl, but you can also mix and match your own
Salty’s on Alki Beach
www.saltys.com/seattle/
1936 Harbor Ave SW, Seattle, WA 98126
We had our wedding reception here so there’s sentimental value.
But we highly recommend going on Sundays for the buffet, and ordering their White Mousse Cake!
I Love Teriyaki
iloveteriyakistoneway.com
3409 Stone Way N Ste 101 Seattle, WA 98103
Order the Spicy Chicken Teriyaki
Seafood City
Not a restaurant, but highly recommend eating in the diner over there for the best Filipino food!
We usually go to Seafood City in Tukwila
I was reviewing for the IELTS by taking practice tests, and came across this interesting passage:
I am firmly of the opinion that most of us, Wegener included, are not in any real sense the authors of our own lives. We plan, think, and act, often with apparent freedom, but most of the time our lives ‘happens to us’, and we only retrospectively turn this happenstance into a coherent narrative of fulfilled intentions.
Whispering Earring
The recent release of Cluely reminds me of the Whispering Earring. This short story was written in 2012: ten years before ChatGPT, six years before Transformers, and four years before OpenAI was founded. I like fiction because it allows us to imagine things that could be, in the most vivid way possible.
The technology that Cluely advertised in their marketing video might be four or five years ahead, but you see traces of it today. I myself use Claude to improve the flow of my writing. I also use Cursor for code. There are definitely semblances to the Whispering Earring, and eerily enough, the implication that “you lose a part of your brain” might be true.
Will you wear the Whispering Earring?
I really enjoy reading Ines Montani’s guide to creating beautiful slides. Although I’ve learned a lot about making slides during my consulting gig, there’s a lot of nuggets in this guide that can transform your presentations from informative to fantastic!
Greatest City in the World
NYC is amazing! I get it now. The food is cheap and delicious, the city runs 24/7, walkable streets and decent public transportation—amazing! When I was young, I really don’t understand why a lot of art seem to “glorify” New York City: from plays, to television, and even music. I guess I get it now. There’s some intensity and rawness that’s present in NYC that other American cities have. Awesome place, really. I get it now.

Obssessing over the e-ink theme
Recently, I’m enjoying “e-ink” themes for some of my websites. For example, the website version of this micro blog tries to emulate this set-up. It is fake e-ink, as I don’t really use these sites in the context of an e-ink reader. I just enjoy these high-contrast and pure black-and-white themes with a “retro aesthetic” as they look timeless and classy.
For example, Obsidian has this gorgeous e-ink mode that I’ve been using since:
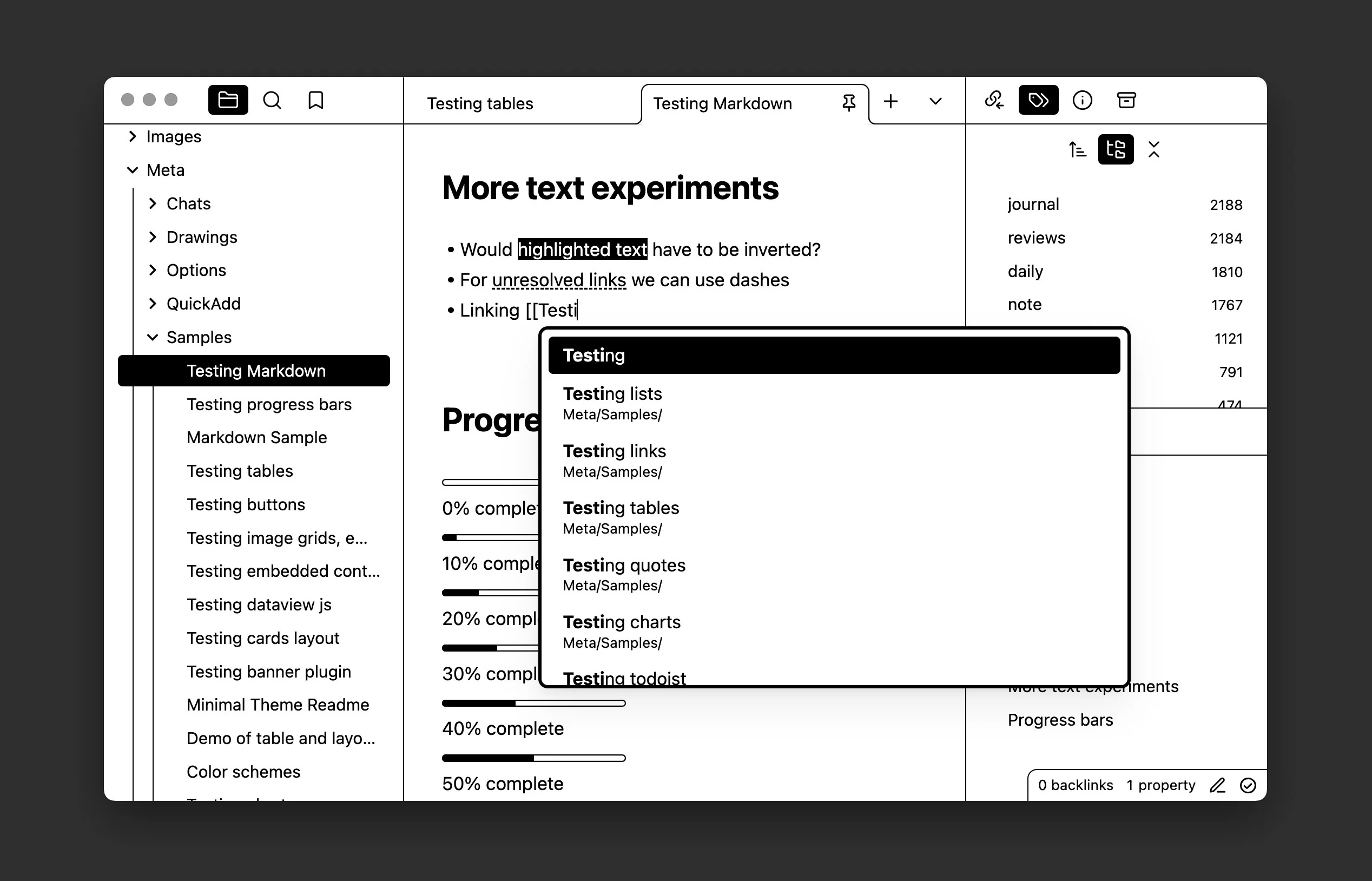
I’ve also been itching to try out this nice Sacred Computer theme, as it embodies the same style and vibe I’m hoping to achieve.
Where I'm getting AI News nowadays
Although I still maintain a Twitter and Bluesky account to follow researcher accounts, I avoid opening these websites as they can get a bit toxic towards both sides of the political spectrum. For the past year, I find the following resources helpful for getting up to date in AI research:
- AI News is really good. Every night they send you a summary of topics and discussions in various social media sites, Discord servers, and subreddits. A good way to get an overview of all things AI.
- Scholar Inbox is perfect for academics. You curate your list of research topics and then they send you recommendations of new arXiv papers that release everyday. This is really nice to get the “first scoop” of preprints before they are announced in social media.
- Interconnects is like Stratechery for NLP written by someone who’s actually in the trenches. A lot of insightful opinions and it gives you a nice synthesis of the field itself.
- r/LocalLlama is probably the best AI/NLP subreddit right now. Most of the comments are informative, and seem to come from actual practitioners. I think it’s a good way to get a general vibe of the field itself.
On building my personal LLM benchmark
Over the past week, I’ve experimented upon building a personal LLM benchmark that tests models based on my specific tastes and requirements. I’d definitely encourage anyone to make their own suites, but it’s very involved. I’ll probably write about my experience soon in an actual blog post…
Anyway, upon investigating my test-cases, I learned that most of the things I care about are a matter of taste and style. For example, I prefer matplotlib code to be done a certain way (using fig, ax = plt.subplots(...) vs direct plt) or concise responses over verbose ones. I wonder if there’s a way we can incorporate these personal preferences during finetuning (assuming we have the resources to do so) with zero-to-few human annotation effort.
This reminds me of a slide from John Schulman’s talk on open problems in High-Quality Human Feedback (we actually took a stab on this problem in a previous work):

Again, this is something I want to write more about in the future. Still organizing my thoughts on this. And by the way, seems like Qwen/Qwen2.5-14B-Instruct-1M is the best model in my personal benchmark so far when accounting for performance and cost-efficiency.
An observation: it seems like tooling for LLM inference diverges between research/academia and industry in some ways. For the past year, I’ve been using a lot of vLLM for inference and (recently) curator for data generation–mostly for research. But I’ve seen a lot of my colleagues from the industry use outlines, LangGraph, and PydanticAI.
Kingdom Come Deliverance II (KCD 2) is so immersive that it might as well be my Game of the Year (I know, it’s too early to say). The potion-making tutorial is so good, it feels like I’m doing it for real!

Blacksmithing is also relaxing! We made so many horseshoes and axes in my first day :)

This is definitely a “game you play during the holidays,” so I can’t wait for summer to sink hours into this gem. I’m still too early to the story yet, but I already recommend this for everyone!
TIL: arXiV-ready LaTeX files from Overleaf
One persistent problem I often come across is how the LaTeX files from Overleaf that I upload to arXiv have source or compatibility errors. Today, I learned that instead of downloading the zip archive to get the LaTeX source, I should use the “Submit” button.
Don’t click the archive button:
Instead, go to your Overleaf project > Submit > Submit Your Papers to ArXiV:

This creates an optimized zip file that is 100% compatible with arXiv!
On Filipino NLP
Over the holidays, I’ve been thinking a lot about what it means to do Filipino NLP now that we’re in the age of LLMs. Multilingual LLMs are getting better and core NLP tasks such as NER or sentiment analysis are now streamlined by models like GPT-4.
I’ve decided to bet on post-training and adaptation. I believe that this unlocks several opportunities for resource-constrained and small Filipino NLP research communities to contribute to a larger whole. Here’s an excerpt from my blog post:
While I still believe in building artisanal Filipino NLP resources, I now see that we need to simultaneously support the development of multilingual LLMs by creating high-quality Filipino datasets and benchmarks. This way, we can actively push for the inclusion of Philippine languages in the next generation of multilingual LLMs, rather than just waiting for improvements to happen on their own.